Complex challenges require special solutions.
Already in the first part of the blog post (“How copying and storing huge amounts of data becomes child’s play”, published on 07. December 2021) we reported about the situation of our customer and our corresponding solution.
What was the challenge exactly?
Our customer has the challenge of outsourcing a large pool of data, which it keeps on its own storage systems, to external, fast storage in order to create space locally for new data. At the same time, however, there is a need to access this outsourced data again at short notice. The restore process must be very fast. The data transfer to the external fast storage system should not take place via a new network, but via the corporate WAN. In the final step, the data is to be stored in a long-term archive for up to 30 years.
So, in response to his challenge, we developed a 3-tier backup and archiving system.
In this second blog, we will now go into a bit more technical depth and show which technologies we used to meet the requirements.
The project at a glance:
✅ > 2 petabytes (PB) of data volume per month.
✅ Across 4 sites & 2 continents
✅ 10 Gbit/s transmission speed
✅ Cost & time savings for restore and archiving.
Solution design
The new future-proof design involves transferring all data from the sites to a central multi-petabyte Ceph cluster, cataloging it in the central database, and ultimately archiving it to the cloud archive storage.
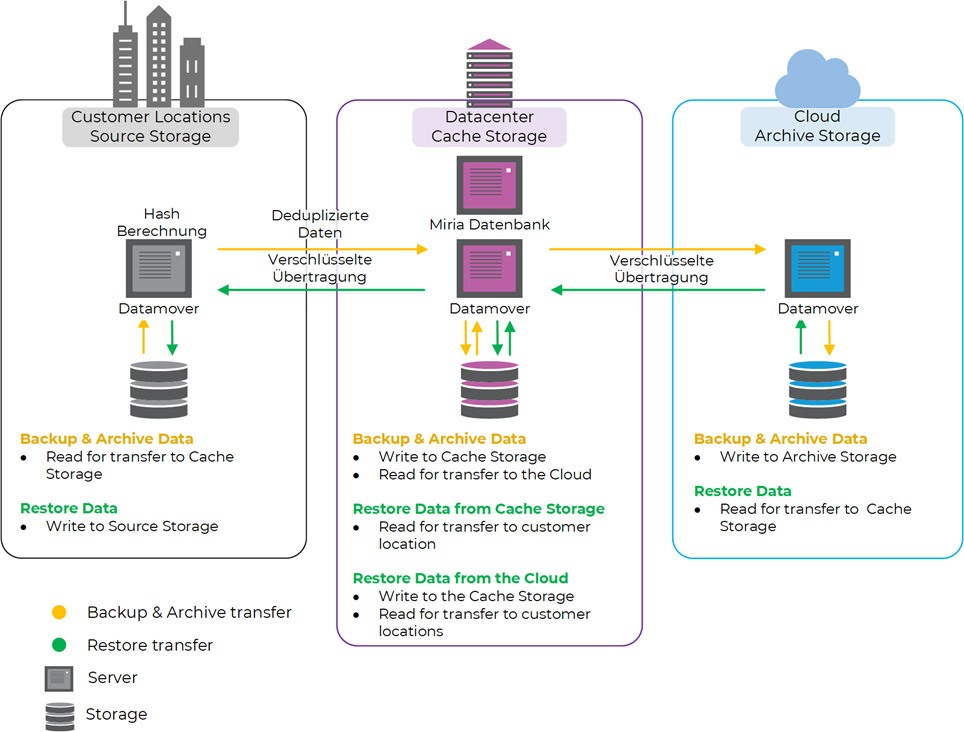
Technology
Since the sites are always redundantly connected to the corporate network, one line is usually not actively used. This enables a startup configuration for each site without network expansion and saves costs in the process.
At each site with storages, multiple Atempo Miria Datamovers handle the ingest of data from the source storage. Datamovers are physical or virtual servers with powerful CPUs for hash computation and simultaneous broadband connectivity for fast data transfer.
When the data is read in, hash values of the files are already created, which are used on the one hand to save bandwidth by means of deduplication and on the other hand to ensure data consistency by verifying the transferred data at the destination.
Deduplication only transfers data to the Ceph storage in the central data center that does not yet exist there or on the cloud storage. This leads to a saving of bandwidth, which is then available for the transfer of new data.
The transfer of data from the source storage to the central Ceph storage is between the site’s Miria data movers, which read the data, and the central data center’s Miria data movers, which write the data to the Ceph storage.
Periodically, new data on the central Ceph Storage is transferred to the cloud – again between the Miria Datamovers at the central data center, which now swap roles and read the data, and the Miria Datamovers in the cloud, which write the data to the archive storage.
The transfer between Datamovers is always encrypted, providing additional protection for the data in transit.
The platform in the central data center represents the data hub. The central Ceph storage is used as cache storage, which automatically deletes the oldest files when a defined fill level is reached, provided that these have already been completely backed up to the cloud archive storage. Only as many files are deleted until a defined minimum fill level is reached.
When restoring files, Atempo’s Miria software automatically determines the best recovery source and starts the appropriate recovery process. If the files are still stored on the central Ceph storage, they can be restored immediately. If the data is already stored exclusively in the cloud archive storage, the provisioning of the files to the cloud archive storage is requested via API and then the recovery to the source system is started automatically.
The combination of the central Ceph Storage as cache storage for fast restores of the latest files in combination with the Archive Cloud Storage for cost-effective long-term archiving of the data offers the advantages of both storage types in one intelligent solution – time savings for restores and cost savings for long-term archiving.
Are you also faced with the challenge of having to securely store and archive very large amounts of data? Faced with the challenge of implementing a solution that can cope with the constant growth of data in the future and does not have to be rethought every year?
Then contact us for a non-binding discussion.


