Komplexe Herausforderungen erfordern besondere Lösungen.
Bereits im ersten Teil des Blogbeitrags („Wie das Kopieren und Speichern großer Datenmengen zum Kinderspiel wird“, veröffentlicht am 07. Dezember 2021) haben wir über die Situation unseres Kunden und unsere entsprechende Lösung berichtet.
Was genau war die Herausforderung?
Unser Kunde steht vor der Herausforderung, einen großen Datenbestand, den er auf seinen eigenen Speichersystemen vorhält, auf externe, schnelle Speicher auszulagern, um lokal Platz für neue Daten zu schaffen. Gleichzeitig besteht aber die Notwendigkeit, auf diese ausgelagerten Daten kurzfristig wieder zuzugreifen. Der Restore-Prozess muss sehr schnell sein. Der Datentransfer zum externen schnellen Speichersystem sollte nicht über ein neues Netzwerk, sondern über das Unternehmens-WAN erfolgen. Im letzten Schritt sollen die Daten in einem Langzeitarchiv für bis zu 30 Jahre gespeichert werden.
Als Antwort auf diese Herausforderung haben wir ein 3-stufiges Sicherungs- und Archivierungssystem entwickelt.
In diesem zweiten Blog gehen wir nun etwas mehr in die technische Tiefe und zeigen auf, welche Technologien wir eingesetzt haben, um die Anforderungen zu erfüllen.
Das Projekt auf einen Blick:
✅ > 2 Petabyte (PB) Datenvolumen pro Monat.
✅ Über 4 Standorte und 2 Kontinente hinweg
✅ 10 Gbit/s Übertragungsgeschwindigkeit
✅ Kosten- und Zeitersparnis bei Wiederherstellung und Archivierung.
Lösungskonzept
Das neue, zukunftssichere Konzept sieht vor, dass alle Daten von den Standorten auf einen zentralen Ceph-Cluster mit mehreren Petabyte übertragen, in der zentralen Datenbank katalogisiert und schließlich in einem Cloud-Archivspeicher archiviert werden.
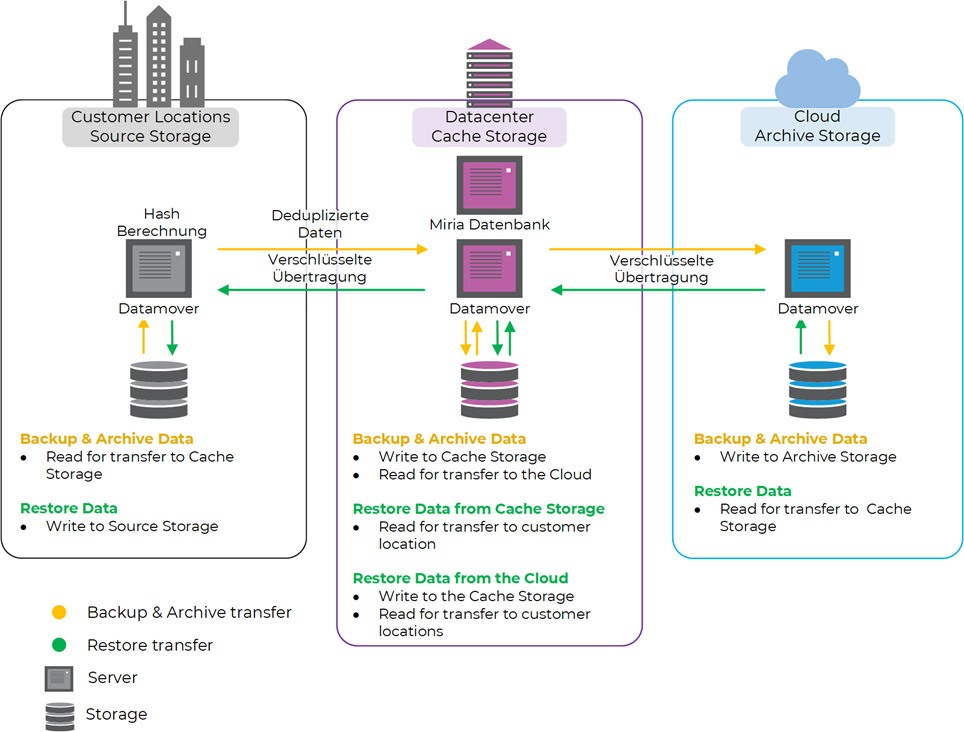
Technik
Da die Standorte immer redundant an das Unternehmensnetz angeschlossen sind, wird eine Leitung meist nicht aktiv genutzt. Dies ermöglicht eine Startup-Konfiguration für jeden Standort ohne Netzwerkerweiterung und spart dabei Kosten.
An jedem Standort mit Speichern übernehmen mehrere Atempo Miria Datamover den Ingest von Daten aus dem Quellspeicher. Bei den Datamovern handelt es sich um physische oder virtuelle Server mit leistungsstarken CPUs für die Hash-Berechnung und gleichzeitiger Breitbandanbindung für eine schnelle Datenübertragung.
Beim Einlesen der Daten werden bereits Hash-Werte der Dateien erzeugt, die einerseits zur Bandbreiteneinsparung durch Deduplizierung und andererseits zur Sicherstellung der Datenkonsistenz durch Verifizierung der übertragenen Daten am Zielort genutzt werden.
Bei der Deduplizierung werden nur Daten auf den Ceph-Speicher im zentralen Rechenzentrum übertragen, die dort oder auf dem Cloud-Speicher noch nicht vorhanden sind. Dies führt zu einer Einsparung von Bandbreite, die dann für die Übertragung neuer Daten zur Verfügung steht.
Die Übertragung der Daten vom Quellspeicher zum zentralen Ceph-Speicher erfolgt zwischen den Miria-Datamovern des Standorts, die die Daten lesen, und den Miria-Datamovern des zentralen Rechenzentrums, die die Daten in den Ceph-Speicher schreiben.
In regelmäßigen Abständen werden neue Daten auf dem zentralen Ceph-Speicher in die Cloud übertragen – wiederum zwischen den Miria Datamovern im zentralen Rechenzentrum, die nun die Rollen tauschen und die Daten lesen, und den Miria Datamovern in der Cloud, die die Daten in den Archivspeicher schreiben.
Die Übertragung zwischen den Datamovern erfolgt immer verschlüsselt, was einen zusätzlichen Schutz für die Daten während der Übertragung bietet.
Die Plattform im zentralen Rechenzentrum stellt die Datendrehscheibe dar. Der zentrale Ceph-Speicher wird als Cache-Speicher genutzt, der bei Erreichen eines definierten Füllstandes automatisch die ältesten Dateien löscht, sofern diese bereits vollständig auf dem Cloud-Archivspeicher gesichert wurden. Es werden nur so viele Dateien gelöscht, bis ein definierter Mindestfüllstand erreicht ist.
Bei der Wiederherstellung von Dateien ermittelt die Miria-Software von Atempo automatisch die beste Wiederherstellungsquelle und startet den entsprechenden Wiederherstellungsprozess. Befinden sich die Dateien noch auf dem zentralen Ceph-Speicher, können sie sofort wiederhergestellt werden. Sind die Daten bereits ausschließlich im Cloud-Archivspeicher gespeichert, wird die Bereitstellung der Dateien im Cloud-Archivspeicher über die API angefordert und anschließend die Wiederherstellung auf dem Quellsystem automatisch gestartet.
Die Kombination aus dem zentralen Ceph Storage als Cache-Speicher für schnelle Wiederherstellungen der aktuellen Dateien in Verbindung mit dem Archive Cloud Storage für die kostengünstige Langzeitarchivierung der Daten bietet die Vorteile beider Speichertypen in einer intelligenten Lösung – Zeitersparnis bei Wiederherstellungen und Kostenersparnis bei der Langzeitarchivierung.
Stehen auch Sie vor der Herausforderung, sehr große Datenmengen sicher speichern und archivieren zu müssen? Stehen Sie vor der Herausforderung, eine Lösung zu implementieren, die dem ständigen Wachstum der Daten auch in Zukunft gewachsen ist und nicht jedes Jahr neu überdacht werden muss?
Dann kontaktieren Sie uns für ein unverbindliches Gespräch.


